Imaginative Coding
Reflecting on the process of programming as if the tools I want to make already existed.
Explored through four example projects:
DRY Config Data Format
Message/Comparator Compositions
Growth Algorithms
Error Handling Flow
25 December 2018
People have told me throughout my life programming that developing my own tools is a waste of time. They fear spirals of unproductive messes and never making any progress on actual work. That tools have been made thousands of times over in many variations and anyone should be able to find a pretty close tool to what they want. This was frustrating as a newer programmer. It felt like people were telling me to stop imagining ways that things could be. To stop wanting better, or if you wanted better it should be the passive kind of wanting, and waiting.
I'm unwilling to accept that kind of restriction on my mind. Desiring better and finding a way towards it is pretty central to my identity, and the practice helps me identify what I want so I can recognize it if I see something close. A friend of mine suggested that I try writing code as if the tool was already made. To speculate instead of going through the effort of making a tool. This of course has limits, the things you imagine never quite work out that way, but nonetheless felt like a way to practice the hopeful part of myself.
Doing so has let me feel what the value of these tools might actually be, and helps refine the vision so that if I do decide to develop one of them, I have more realized uses to direct the effort. Sometimes I'm using pseudocode to explore a potential api or to map out the architecture of a system. Other times it's making up syntax for instances or operations that I want to be more expressive. Here are summaries of a few examples. I plan on expanding upon each of these in later posts.
DRY Config Data Format
I've worked on projects that use JSON with JSON Schema as well as a custom .ini file format that supported includes and object extension with property overrides. Using both of these lead to a desire for aspects of each, and for more features to fill some gaps. I want to avoid unnecessary repetition, and allow the data to be formatted in a way that matches how designers think about the problem. If something is modeled as an equation, the format should support that. If the same data is applicable in multiple places, it should be straightforward to re-use. I took a look at existing alternatives, such as YAML and TOML, and hjson, but none satisfied the desires that I had. Out of all of them hjson with some user-level extensions would probably come closest, but I wanted to let myself experiment, so I started prototyping syntax for the features that I wanted and implemented some of them in a python parser. Some of the syntax is inspired by CSS and an extension Less. The features that I desired are:
- Shared data defintions
- Object extension/overrides
- Type definitions / schema / data validation
- Multiple configurable ways to describe the same type of data
- Minimal superfluous syntax
An annotated example of the syntax I played with is below:
.Character: ${ // type definition
inherit_from: Entity
required_members: {
StatValues: ${ // member type by definition
type: Array
length_min: 1
} // commas between members optional with newline
UniqueID: Guid // member type by name
}
optional_members: {
HideBefore: DateTime
}
}
.Guid: ${
one_of: [
${ type: string
length: 32
allowed_characters: [
0..9 // terse range syntax
a,b,c // newline implies comma
d,e,f // or you can use it explicitly
]
}
${ type: uint
min: 0
max: (1<<128)-1 // formulas allowed, no side effects allowed
}
]
}
@SharedStatValues: [10, 11, 12, 15, 18, 25]
// can specify type of an object
Alice(Character): { // for polymorphism or top-level items
StatValues: @SharedStatValues
}
Bob(Character): {
StatValues: [8, 9, 9, 10, 10, 11]
}
Message/Comparator Compositions
I've worked on projects that have a very wide broadcasting system, and specific messages. Unity's BroadcastMessage vs SendMessage is an analagous relationship. Sometimes these are implemented via reflection, and other times with delegates. Sometimes messages are queued up and responded to later, othertimes responses are executed immediately. If messages are enqueued, responders usually but not always make a decision about whether to use the message at the time it is taken out of the queue, not when it was put in. A single project can have several of these kinds of systems, depending on the surrounding structures and requirements. However these numerous systems all center around a concept of code communication with the help of a little decoupling.
When these systems are too dynamic/runtime driven, I've found debugging/introspection difficult. Especially since message systems often have the drawback of losing information about causality, particularly with a queue where you do not have the stack frame, or when done through reflection. So I wanted to think about something with a stronger type system, but didn't require writing and maintaining copies of similar types of messages and comparators that shared common data. A terse entity-component system readily seemed like a good solution. Like with the previous problem I started with abstract syntax, and then later on tried out some varying levels of implementation, this time in C#. C# lacked a type system that could support the functionality that I wanted without some very verbose workarounds and manual maintenance of guarantees. Additionally, some checks could not be performed at compile time and had to be done at runtime instead. It was rewarding to explore what other academics or languages had considered for solutions to these type system problems.
Event Message and Parameters
public class Message<P1..PN> : IMessage
where P1 : IParametersComponent,
... PN : IParametersComponent
{
public readonly P1 parameters1;
...
public readonly PN parametersN;
public Message(P1 p1 .. PN pN)
{
parameters1 = p1;
...
parametersN = pN;
}
}
public class Params_Actor : IParametersComponent
{
public readonly EntityID actorID;
public Params_Actor (EntityID actorID)
{
this.actorID = actorID;
}
}
Event Comparators
public class Comparator<MessageType>
where MessageType : Message
{
ComparatorComponent<MessageType.P1> comparator1;
...
ComparatorComponent<MessageType.PN> comparatorN;
public ComparatorResult EvaluateMessage (MessageType message)
{
var result = ComparatorResult.Neutral;
result = And(result, comparator1.EvaluateEventComponent(message.parameters1));
...
result = And(result, comparatorN.EvaluateEventComponent(message.parametersN));
if (result != ComparatorResult.Accept) {
return ComparatorResult.Reject;
}
return ComparatorResult.Accept;
}
}
delegate ComparatorResult EntityComparator(EntityID entity);
public class Comparator_Actor : ComparatorComponent<Params_Actor> {
readonly EntityComparator entityComparator;
public ComparatorComponent<Params_Actor>(EntityComparator entityComparator)
{
this.entityComparator = entityComparator;
}
public override ComparatorResult EvaluateComponent (Params_Actor eventParams)
{
var result = ComparatorResult.Neutral;
if (entityComparator != null) {
result = entityComparator(eventParams.actorID);
if (result != ComparatorResult.Accept) {
return ComparatorResult.Reject;
}
}
return result;
}
}
Usage Example
class BattleStart : Message<> {} // defining a new message type is now terse
class CharacterDeath : Message<Params_Actor> {}
public class Team
{
HashSet<EntityID> teamMembers;
int deathCount;
public void SetupEventListeners()
{
var compareBattleStart = Comparator<BattleStart>();
var compareTeamMemberCharacterDeath = Comparator<CharacterDeath>(
Comparator_Actor(entityComparator=this.IsEntityAMember));
var manager = MessageManager.Get();
manager.RegisterForEvent<BattleStart>(
compareBattleStart,
this.ResetDeathCount);
manager.RegisterForEvent<CharacterDeath>(
compareTeamMemberCharacterDeath,
this.IncrementDeathCount);
}
public bool IsEntityAMember(EntityID entity) {
return teamMembers.Contains(entity);
}
private void MarkCharacterDeath(CharacterDeath death) {
teamMembers.Remove(death.parameters1.actorID);
deathCount++;
}
private void ResetDeathCount() {
deathCount = 0;
}
}
The general idea is that this lets Comparators be re-used and even defined in data, rather than each recipient iplementing accept/reject criteria.
It would be nice if the class Comparator_Actor : ComparatorComponent<Params_Actor> could have some way of guaranteeing a 1-1 type mapping, where for each Params_ there is exactly one Comparator_ and you have a compile time way of accessing it. Something similar to C++ template specialization could perhaps achieve this, if you specialize ComparatorComponent on each Params_. Another feature you see used here that I have come to like is ternary logic: Neutral/Accept/Reject, None/True/False, Unset/On/Off, etc. It's a shame that they don't have built-in support for most languages and instead must be constructed in userspace.
Growth Algorithms
I've had fantasies about being able to program with DNA. To write complicted, compact instructions that reveal themselves with time through intricate external processes. Protein folding is a very hard problem to predict. Our understanding of genes is still relatively basic, limited to the binaries of presence and expression. Our understanding of protein mechanisms is still largely example driven, not systematic. And yet, I believe we can get there. CRISPR promises much more opportunity for experimentation, and is just the beginning. I want to program seeds that can be planted and will grow into a house. I want to program plants to grow complicated materials, guided by designer intention instead of transposing existing genes for existing materials to bacteria for production.
These dreams may be far off, but there are some more achievable ones that are still inspiring to me. Driven partly by this long term goal and partly by some aesthetic directions, I wanted to be able to describe a process for the growth of shapes over time. To have a terse language for expressing direction, but more understandable than the fifth order effects of DNA sequences. Then I stumbled across this video by some researches at the MIT Media Lab. Never before had the possibility for life borne from simple functions been more clear to me.
The structures in this video are generated with a consistent method of adjusting the mesh from frame to frame, searching to optimize for a given function. Several different functions are demonstrated in the video, and they produce such radically different forms. And they look so much like real living things. It struck me as a reasonable possibility that growing cells produce proteins or other structures with proteins that lead to some of the optimization functions given. Maximizing area while minimizing volume is a perfect direction for lungs to be able to pick up air. Spreading out through a volume while using as little material as possible is readily related to the paths that nerves and blood vessels form.
I can see so many potential next steps to this that I feel giddy every time I think about it. The structures in the video above are grown using a single optimization function uniformly across the entire object for the full duration of the sequence. But making adjustments over time, and targeting areas with different types of growth, sound just like the kinds of behavior that life could achieve and would enable the wildly more complex shapes that we see represented in organisms. So what might a language look like that describes these operations? the selectors of location and directors of change. Perhaps something like this imaginary language could even provide a level of abstraction connecting DNA and protein folding with the macro structures of form and function.
An Optical Example
Eyes have been independently developed by multiple branches on the tree of life. Being able to focus and perceive light has been valuable enough and achievable enough. What would some simple instructions in the langauge of surface level optimizations look like to create a primitive eye? With the development of photoreceptors and how to connect them to a feedback/nervous system, this could get incredibly complicated. So let's instead reduce it to the physical shapes involved with a pinhole camera.
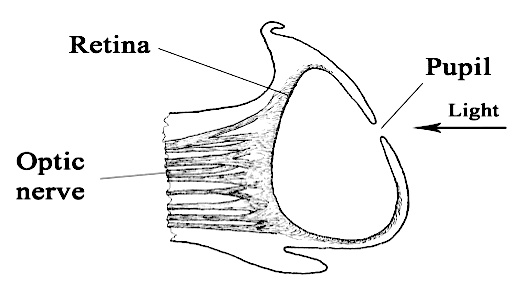 Evolution of the Eye and Visual System. Cronly-Dillon & Gregory. page 374
Evolution of the Eye and Visual System. Cronly-Dillon & Gregory. page 374
Imagined Procedure
GrowthPerimeter perimeter = GrowthPerimeter(
shape: circle,
radius: 20,
point_distance: 0.2)
Position origin = Position(0,0)
Position pupil = Position(20,0)
Scalar pupil_radius = 1
perimeter.apply_label(
selector: Selector_DistanceFromPosition(
position: pupil
comparator: LessThanOrEqualTo
distance: pupil_radius)
label: "Retina")
perimeter.apply_label(
selector: Selector_WithoutLabel("Retina")
label: "Edge")
Scalar cavity_wall_thickness = 3
Vector away_from_pupil = Vector(Angle(0.5)) // Angle in Tau
Position opposite_pupil = Position(-20, 0)
Selector near_opposite_pupil = Selector_DistanceFromPosition(
position: opposite_pupil
comparator: LessThanOrEqualTo
distance: cavity_wall_thickness)
perimeter.apply_growth(
selector: Selector_Label("Retina")
director: Director_InDirection(away_from_pupil)
while_condition: Condition_SelectorEmpty(
Selector_Label("Retina").Intersect(near_opposite_pupil)))
Selector too_close_to_edge = Selector_DistanceFromPoints(
aggregator: Minimum
operand_selector: Selector_Label("Edge")
comparator: LessThanOrEqualTo
distance: cavity_wall_thickness)
perimeter.apply_growth(
selector: Selector_Label("Retina").Exclude(
too_close_to_edge)
director: Director_FleePosition(origin)
until_condition: Condition_SelectorEmpty(retina_to_expand))
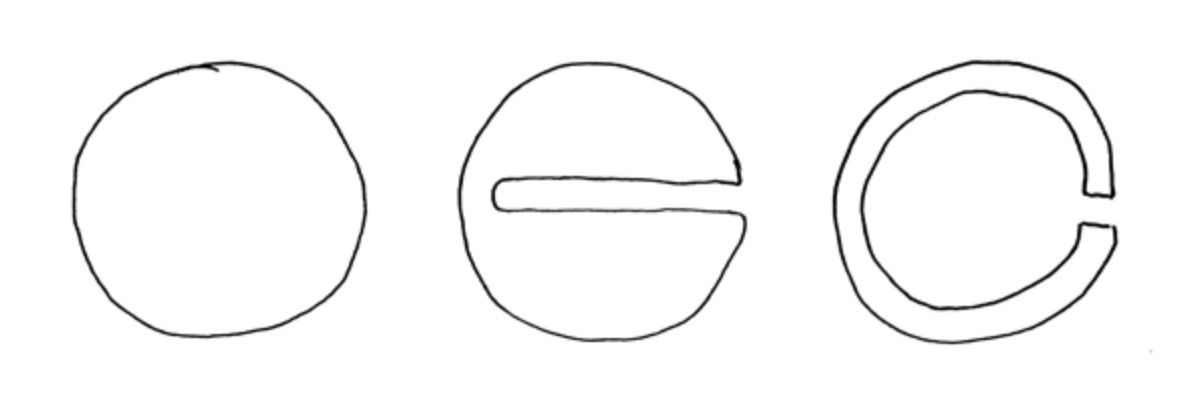 Resulting steps of the procedure
Resulting steps of the procedure
This code feels a little verbose, and in such a different format than the visual processes that I use in my mind when planning the steps. Next steps could involve visual feedback for the directions that are being written: highlighting selectors and drawing the directors resulting vectors. I also have been experimenting with random growth using a few simple selectors and directors. Hooking this randomness of instructions up to a genetic algorithm and picking fit examples from each generation manually could be a satisfying way to explore the posibility space.
Error Handling Flow
Many functions or procedures that I write have a section at the beginning dedicated to parameter validation. Defending against null pointers, invalid string identifiers, out of range values, parallel vectors with mismatched lengths, etc. Additionally, there is also error checking throughout a procedure body as you call into other procedures that may fail. Collectively, all of this validation code can obscure the core intent of the procedure. Some of this could be handled by a dependent type system, where a value's type is informed by the value itself, not just assigned. So a string could be a CharacterIdentifier if it was a valid one, but could not be if it were not. While dependent types are not a common language feature this can be approximated with algebraic types in in many functional languages. Additionally, a limited version is available in C-like languages in the form of constructors that can fail, either by throwing an exception or having a factory function that returns a boxed value that may not be set such as Optional<T>.
Similar to the message system, it would be nice if the input validation could be performed in a distinct place from the core logic of the function. If these concepts are codified in the type system and can be checked/guaranteed at compile time, then the type definitions themselves perform the role of validation. This also has the benefit of consolidation since the same pattern of checking would otherwise need to be done at each point of use. Here are some steps in that direction with simple additions to a structure based on NamedType.
template <typename T, typename Tag>
class ValueCheckedType : NamedType<T, Tag>
{
typedef T UnderlyingType;
static Optional<ValueCheckedType> TryCreate (const T& t)
{
if (CheckValue<ValueCheckedType>(t))
{
return Optional<ValueCheckedType>(ValueCheckedType(t));
}
else
{
return Optional<ValueCheckedType>();
}
}
Bool PostDeserialize() const
{
if (!CheckValue<ValueCheckedType>(m_Value))
{
return false;
}
return true;
}
private:
// don't expose a public constructor that takes T or nothing, instead see TryCreate
// only for use by Deserialization, and perhaps some Pointer classes
// explicitly allowed with friend functions/classes
ValueCheckedType() : m_Value() { }
ValueCheckedType(const T& t) : m_Value(t)
{
CheckValue<ValueCheckedType>(m_Value);
// can't do anything with return of CheckValue here
// could use exceptions if your environment/style supports them
}
}
template<typename T>
static Bool CheckValue(const T::UnderlyingType& t);
using CharacterIdentifier = ValueCheckedType<string, struct CharacterIdentifierTag>;
template<>
static Bool CheckValue<CharacterIdentifier>(const string& sCharID)
{
return CharacterManager::Get()->IsValidCharacterIdentifier(sCharID);
}
The above structure is much less imaginative coding and more of an actual implementation but it was nice to spend a little bit of time justifying the idea that many of these types of error checks can be done by the type system and therefore don't require any code per function. Most of my imaginative coding exercises do readily turn into actual code. Part of the benefit is that imagining what something could be like provides a hefty dose of inspiration, and a direction to head towards. Most of my implementations have not reached the level of imagined features or capacity, but are already useful in their partially complete states.
Coming back to the domain of error handling, the remaining types of errors that we have are procedure failures. These are often handled by exceptions in languages/environments that support them. However I have never really been fond of them. For one, exceptions in C++ are slow on gaming consoles and mobile devices, but also even when they are fast/available I don't like the distributed nature of them. It's unclear where the points of failure are, unless you wrap each potential failure in its own try/catch. Instead, in the codebases that I work in and create, usually there are multiple return values. Sometimes this is implemented with out parameters, or with language-level multiple return values, or with a return structure (such as the aforementioned Optional<T> or ErrorOr<T>). This has been the dominant style in Go, and it's been relatively clear. However I still have some issues with it for being too verbose/repetitive. Some other language's features in this direction have perhaps hidden the failure locations too readily, such as C#'s ? operator that will silently ignore a null. This seems like a crutch to compensate for the fact that C# objects are all nullable. After a few mutations from an exceptional style, while trying to stay in a Go environment, I came up with the following:
// this is pretty close to an exceptional style
// but each line that can fail is clearly labeled.
var err = nil;
do {
var file, err = open(file_name);
if (nil != err) break;
defer cleanup(file);
var size, err = getsize(file);
if (nil != err) break;
var file_contents, err = malloc(size);
if (nil != err) break;
defer delete(file_contents);
} while(false);
if (nil != err) {
// handle or propagate error
}
return;
I had some thoughts about how this could have been developed at a user level to be more terse if there was a way to give a procedure access to the parent scope, and allow it to return. Macros can do this in C++ because they are just a pre-processor text replacement. However macros can quickly confuse introspection tools, so I don't like the idea of relying on them for something as common and integrated as error checking. Additionally, though it was a desire I started out with, returning in the parent context from within a macro call is not a very legible choice.
It turns out that the Go developers have also been thinking about how to improve the language features around error handling to make clear messages more readily achievable and reduce boilerplate text that interferes with program readability. It was encouraging that the direction I was headed in with imaginative coding was already being explored by the language developers for an environment that I use regularly. I recommend checking out the linked post. In addition to providing a near-future example they also cover other languages error handling features. I decided to move forward in another way by writing a C++ macro to approximate the above behavior as a proof of concept.
#define CHECK(function_call) \
// this is a gcc extension to both allow assignment \
// and avoid evaluating function_call > once \
({ \
auto value = function_call; \
if(value.IsError()) { \
Error result = handle(value.GetError()); \
if (result != kErrorIgnoreAndContinue) { \
return result; \
} \
} \
value.GetValue(); \
})
// usage:
auto handle = [&file_name](Error error) -> Error {
return error.wrap("File operations failed: %s", file_name);
}
File file = CHECK(open(file_name));
size_t size = CHECK(getsize(file));
I wanted to share some of my experiences with this way of exploring programming. It has been rewarding for me in that it feeds my creative process, inspires domain exploration, and directly leads to tangible steps and projects. As I mentioned at the beginning, I plan to elaborate on each of the above projects/goals in future posts. I hope you've enjoyed seeing some of the things that I've been thinking about and working on, and I hope that you are encouraged to try this process out for yourself. Please feel free to email or tweet at me with questions, comments, and feedback. I'll also be implementing an RSS feed and comments section in the coming months.
 RSS/Atom Feed
RSS/Atom Feed
 Twitter
Twitter